
딥러닝
1.딥러닝이란?
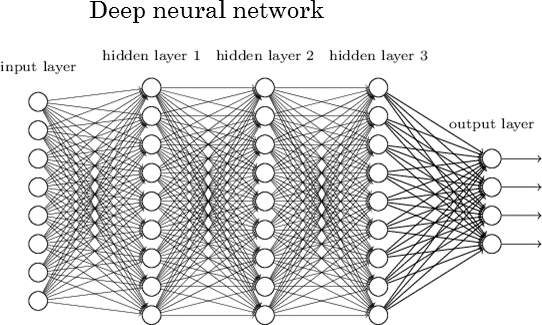
딥러닝 - 심층 신경망이란 3층이상의 깊은 계층을 가진 신경망의 총칭
딥러닝의 등장배경
네트워크의 심층화와 대규모화로 더 높은 일반화 성능을 실험적으로 달성 할 수 있게 되었다.
가설(어떤 원리가 작용하는지)
1.소수의 파라미터 수로 복잡한 함수를 표현할 수 있다.
2.대규모화 되면서 국부 최적해가 비슷한 비용을 갖기 쉬워졌고 비교적 간단하게 좋은 국부 최적해를 발견할 수 있게 되었다
2.딥러닝이 등장하기까지의 기술적 배경
심층 신경망과 그렇지 않은 신경망을 나누는 것은 네트워크의 구조다.
초기 딥러닝은 1990년대에 이미 제안되어 있었다. 이때는 기술적 한계로 인한 것이였다.
문제를 보완할 정도의 빅데이터가 없는한, 높은 일반화 성능을 실현하기는 어려웠다.
빅데이터를 비교적 쉽게 이용할 수 있게 된 것은 2000년대 이후의 폭발적인 정보통신기술의 발전에 의한 것이다.
또한 계산량이 방대는데 과거에는 이것을 할수 없었다.
이처럼 딥러닝은 최근 하드웨어 기술과 빅데이터의 혁신으로 재발견된 것이다.
3.딥러닝에서 이용되는 기술(1)
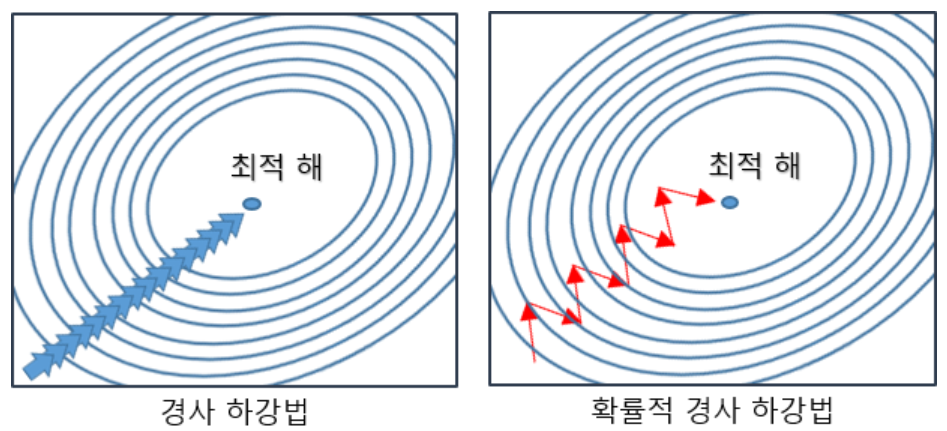
확률적 경사하강법(Stochastic Gradient Descent, SGD) - 확률적으로 데이터를 추출해 기울기를 계산하고 파라미터를 갱신한다.
신경망 학습의 목적함수는 대부분 각 데이터 레코드에 대해 평가한 우도의 평갓값이 된다.
이 목적 함수를 엄밀하게 최적화하면 각 단계에서 데이터의 총 수만큼 계산 비용이 발생한다.
이것을 확률적 경사하강법으로 풀어낸다.
빅데이터에 대한 딥러닝에서는 모든 데이터를 이용해 기울기 정보를 계산하는 것은 현실적이지 않다.
그래서 확률적 경사하강법을 이용한다.
4.딥러닝에서 이용되는 기술(2)
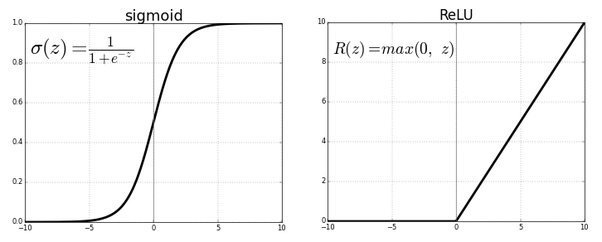
ReLU(Rectified Linear Unit) - 함수는 음의 입력에 관해서는 미분이 0 이 되지만, 양의 입력에 관해서는 항상 1 이 되도록 정의한 함수
이런 것들을 학습 안정화 기술이라고 한다.
기울기 소실로 불리는 현상은 신경망에 관해 계산한 미분이 아주 작은 값을 가지는 상황을 가리킨다.
시그모이드 함수의 미분은 입력이 0에서 멀어지면 급속히 0에 가까워진다.
딥러닝에서 학습 신호는 이 작은 미분값을 서로 곱해 계산되므로, 시그모이드 활성화 함수를 이용하여 구성한 신경망에서는 학습 신호가 소실되기 쉽다.
학습안정화 기술 - ReLU 함수, 데이터 정규화, Xavier 초기화, 배치 정규화, 사전학습, Residual 결합의 도입, LSTM
5.딥러닝에서 이용되는 기술(3)

드롭아웃 - 랜덤하게 뉴런을 골라내 각 학습단계에서 제외하는 방법
딥러닝의 정규화 방법중 하나이다.

데이터 어그멘테이션 - 편집을 통해 데이터를 부풀려 모델의 일반화 성능을 향상하는 방법
데이터의 특성에서 기대되는 모델의 불변성에 착안하는 방법이다.
본 내용은 그림으로 배우는 DataScience 데이터 과학을 참고한 내용입니다
출처: https://continuous-development.tistory.com/210?category=833358 [나무늘보의 개발 블로그]
'Data scientist > Data Science' 카테고리의 다른 글
| [Dacon] 행동 데이터 분석 인공지능 AI 경진대회 2등 코드 분석 (0) | 2021.07.04 |
|---|---|
| [Data Science] 데이터 사이언스 개념 - 9.신경망이 기초 (0) | 2021.01.15 |
| [Data Science] 데이터 사이언스 개념 - 8.토픽 모델 / 네트워크 분석 (0) | 2021.01.14 |
| [Data Science] 데이터 사이언스 개념 - 7.비지도 학습 (0) | 2021.01.14 |
| [Data Science] 데이터 사이언스 개념 - 6.분류문제 (0) | 2021.01.14 |
