반응형

머신러닝에서 가장 많이 사용되는 scikits learn을 통해 분류 모델에 대한 학습을 해보겠다.

데이터 셋과 모델링/ train과 test를 나누는 라이브러리를 가져온다. 여기서 사용할 모델은 DecisionTreeClassifier이다.
train_tesT_split은 데이터를 쪼개기 위해 사용한다.

이것과 더불어 데이터를 핸들링하고 다루기 위한 pandas와 numpy를 가져온다.

데이터를 봤을 때 이런 형태로 데이터가 들어가 있다.
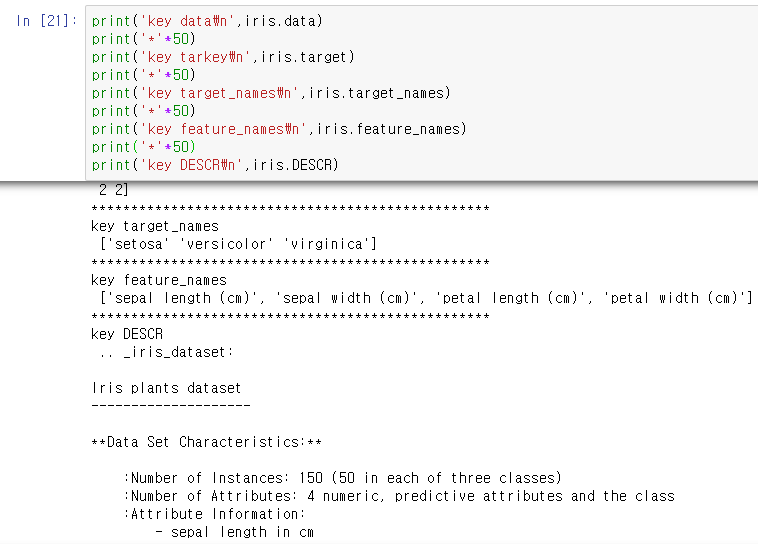
data는 feature(독립변수)가 들어가 있고 targe에는 종속변수가 들어가있다.
여기서 기본적인 정보들을 확인한다.

이제 feature 데이터 셋을 가져온다.
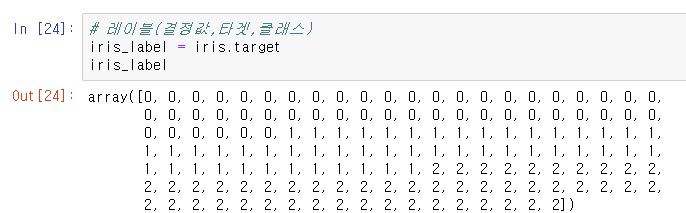
레이블 값도 가져온다.

이제 이 값들을 사용하기 위해 데이터프레임으로 만든다.

만들었던 데이터를 머신러닝을 통해 돌리기 위해 데이터를 분리한다. 우리는 답을 알고있는 train 데이터에서 X_train, y_train, X_test, y_test를 만든다. 이것들을 통해 모델을 학습시키며 학습시킨 모델의 성능을 파악할 것이다.

이부분에서 학습에 쓰일 알고리즘을 선책하고 그 알고리즘에 내가 가지고 있는 train 데이터로 모델을 fit하는 작업을 가진다. 모델에 내가 가진 데이터를 통해 학습 한다고 생각하면 된다.

학습시킨 모델을 통해 예측(predict)을 한다. 그 예측하는 값을 X_test로 한다. X_test를 통해 해당 학습이 예측을 하고 이 예측한 값과 실제 값인 y_test를 비교한다.

이 두개를 비교를 하는데 있어서 accuracy_score 이다. 정확도 분석할 때 사용되는 함수이다. 이런식으로 분류를 하였다.
반응형
'Data scientist > Machine Learning' 카테고리의 다른 글
| [ML/DL] python 을 통한 결측값 확인 및 결측치 처리 방법 (0) | 2020.10.28 |
|---|---|
| [ML/DL] 데이터 인코딩 - Label Encoding / One-hot Encoding/ dummies (0) | 2020.10.28 |
| [ML/DL] 대체법의 종류와 다중 대체법 사용법 (1) | 2020.10.27 |
| [ML,DL] 머신러닝에 대한 간단한 개념들과 사용 하는 주요 패키지 (0) | 2020.10.27 |
| [ML/DL]결측치의 종류와 결측치 처리 가이드라인 (0) | 2020.10.26 |
