분류(classification) 성능평가지표
#metrics 서브 패키지
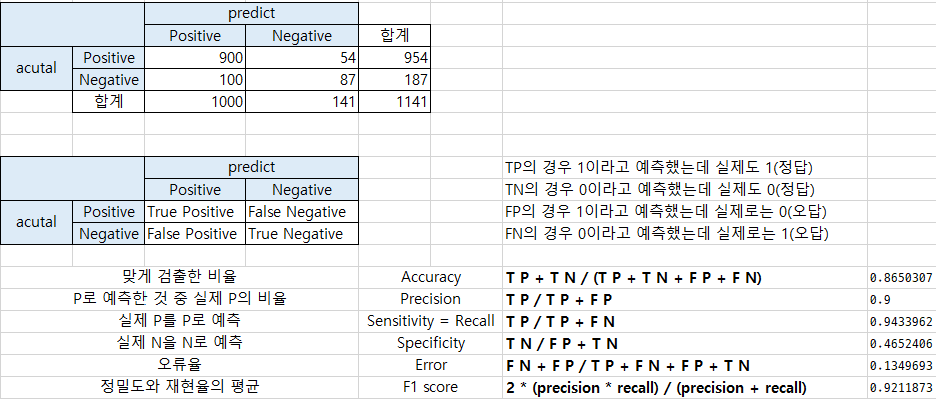
confusion_matrix(answer, prediction) == 오차 행렬
=> 오차 행렬은 어떠한 유형의 예측 오류가 발생하고 있는지를 함께 나타내는 지표이다. 즉 분류의 성능을 평가하는 행렬이다.

# 이진 분류표
# 제품을 생산하는 제조공장에서 품질 테스트를 실시하여 불량품을 찾아내고 불량품을 공장으로 돌려보낸다(recall)
# 품질 테스트의 결과가 양성 -> 불량품 예측한 것이고
# 음성 -> 정상제품이라고 예측한 것이다.
#TP : 불량품(P)을 불량품(P)으로 정확하게 예측 - True
#TN : 정상제품(N)을 정상제품(N)으로 정확하게 예측 - True
#FP : 정상제품(N)을 불량품(P)이라고 예측 - False
#FN : 불량품(P)을 정상제품(N)이라고 예측 - False
y_true = [1,0,1,1,0,1]
y_pred = [0,0,1,1,0,1]
confusion_matrix(y_true,y_pred)
2 => 0을 0으로 예측한 것 2 개
0 => 0을 1로 예측한 것
1 => 1을 0으로 예측한 것
1 => 1을 1로 예측한 것
# 예를 통한 오차 행렬 정리
재현율(recall_socre)이 상대적으로 더 중요한 지표는 실제 positive 양성인 데이터 예측을 Negative로 잘못 판단하게 되면 업무상 큰 영향이 발생하는 경우
ex) 암 진단, 금융사기 판별
정밀도(precision_score)가 상대적으로 더 중요한 지표인 경우는 실제 Negative 음성인데 데이터 예측을 positive양성으로 잘못 판단하게 되면 업무상 큰 영향이 발생하는 경우 :
ex) 스팸메일
예시)
from sklearn.preprocessing import LabelEncoder
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_score
import pandas as pd
import numpy as np
import warnings
warnings.filterwarnings('ignore')
### fit() 메서드는 아무 것도 수행하지 않고, predict()는 Sex 피처가 1이면 0, 그렇지 않으면 1로 예측하는 단순한 분류기 생성
from sklearn.base import BaseEstimator
class MyDummyClassifier(BaseEstimator):
# fit 메서드는 아무것도 학습하지 않음
def fit(self, X, y=None):
pass
# predict 메서드는 단순히 Sex 피처가 1이면 0, 아니면 1로 예측
def predict(self, X):
pred = np.zeros( (X.shape[0],1) )
for i in range(X.shape[0]):
if X['Sex'].iloc[i] == 1:
pred[i] = 0
else :
pred[i] = 1
return pred
titanic = pd.read_csv('titanic_train.csv')
titanic.head()
titanic.info()
titanic_label = titanic['Survived']
titanic_label.head()
titanic_feature_df = titanic.drop(['Survived'],axis=1)
titanic_feature_df.head()
## Null 처리 함수
def fillna(df):
df['Age'].fillna(df['Age'].mean(), inplace=True)
df['Cabin'].fillna('N', inplace=True)
df['Embarked'].fillna('N', inplace=True)
df['Fare'].fillna(0, inplace=True)
return df
## 머신러닝에 불필요한 피처 제거
def drop_features(df):
df.drop(['PassengerId', 'Name', 'Ticket'], axis=1, inplace=True)
return df
## Label Encoding 수행
def format_features(df):
df['Cabin'] = df['Cabin'].str[:1]
features = ['Cabin', 'Sex', 'Embarked']
for feature in features:
le = LabelEncoder()
le.fit(df[feature])
df[feature] = le.transform(df[feature])
return df
## 앞에서 실행한 Data Preprocessing 함수 호출
def transform_features(df):
df = fillna(df)
df = drop_features(df)
df = format_features(df)
return df
titanic_feature_df = transform_features(titanic_feature_df)
X_train, X_test, y_train, y_test = train_test_split(titanic_feature_df,titanic_label,test_size=.2,random_state=10)
dummy_model = MyDummyClassifier()
dummy_model.fit(X_train,y_train)
y_pred = dummy_model.predict(X_test)
print('accuracy {}'.format(accuracy_score(y_test,y_pred)))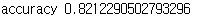
from sklearn.metrics import recall_score, precision_score
def display_eval(y_test,y_pred):
confusion = confusion_matrix(y_test,y_pred)
accuracy = accuracy_score(y_test,y_pred)
precision = precision_score(y_test,y_pred)
recall = recall_score(y_test,y_pred)
print(confusion)
print('*'*50)
print()
print('정확도:{},정밀도 : {}, 재현율:{}'.format(accuracy,precision,recall))
from sklearn.linear_model import LogisticRegression
# 로지스틱 회귀
lr_model = LogisticRegression()
lr_model.fit(X_train,y_train)
prediction = lr_model.predict(X_test)
display_eval(y_test,prediction)

print('accuracy : ',(104+45)/(104+13+17+45))
print('recall : ',(47)/(47+15))
print('precision : ',(45)/(47+16))

# [실습] - 유방암 관련 데이터 - 정확, 재현율(실제 P를 N으로 예측해서는 안된다.)
# 재현율은 실제 양성을 양성으로 예측한 비율이므로 높을수록 좋은 성능모형이라 판단 할 수 있다.
from sklearn.datasets import load_breast_cancer
from sklearn.ensemble import RandomForestClassifier
from sklearn.preprocessing import LabelEncoder
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_score
import pandas as pd
import numpy as np
import warnings
warnings.filterwarnings('ignore')
cancer = load_breast_cancer()
print(type(cancer))
cancer.keys()
cancer_df = pd.DataFrame(data=cancer.data, columns=cancer.feature_names)
cancer_df.head()

cancer_df['target'] = cancer.target
cancer_df.head()cancer_df['target'] = cancer.targetcancer_df.head()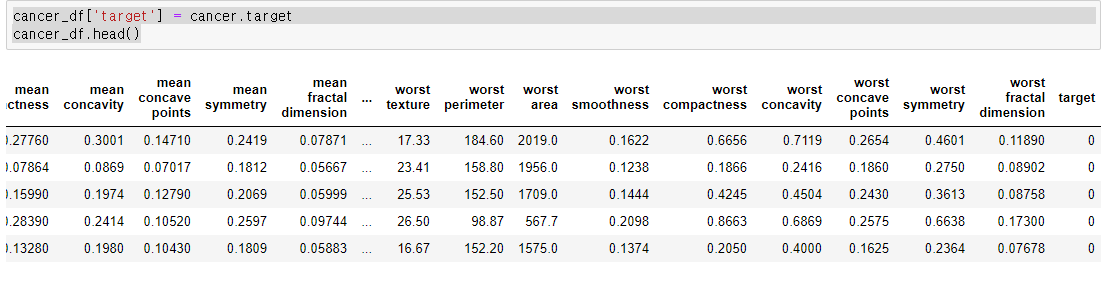
# 분류 학습기 생성
# 팍습 및 평가(교차검증)
# 평가지표에 대한 평균값
# accuracy, precision, recall
X_train , X_test , y_train, y_test = train_test_split(cancer_data , cancer_labe ,
test_size=0.2,
random_state=20)
lr = LogisticRegression()
lr.fit(X_train,y_train)
lr_pred = lr.predict(X_test)
print( '예측 정확도 : {0:.2f}'.format( accuracy_score(y_test, lr_pred)))
from sklearn.model_selection import cross_val_score, cross_validate,KFold
from sklearn.metrics import make_scorer
fold = KFold(n_splits=20,random_status=1,shuffle=True)
scoring = {
'accuracy' :,
'precision' : ,
'recall' :
}
result = cross_validate(lr,cancer_data,cancer_labe,scoring=scoring , cv=fold)
print(result.key())
이렇게 result의 key값을 보면 여러 값들이 들어가 있다.
# 평가지표에 대한 평균값을 구해보자
print('accuracy',np.round(result['test_accuracy'].mean(),2))
print('precision',np.round(result['test_precision'].mean(),2))
print('recall',np.round(result['test_recall'].mean(),2))
print('f1_score',np.round(result['test_f1_score'].mean(),2))
이 값을 key를 통해 값을 빼면 위와 같이 나오게 된다.
'Data scientist > Machine Learning' 카테고리의 다른 글
| [ML/DL] python 으로 구현하는 ROC곡선과 AUC (0) | 2020.11.02 |
|---|---|
| [ML/DL] 정밀도와 재현율의 트레이드 오프 정의와 구현 (0) | 2020.11.02 |
| [ML/DL] python 을 통한 교차검증 ( k -Fold , stratifiedkFold) (0) | 2020.10.28 |
| [ML/DL] python 을 통한 결측값 확인 및 결측치 처리 방법 (0) | 2020.10.28 |
| [ML/DL] 데이터 인코딩 - Label Encoding / One-hot Encoding/ dummies (0) | 2020.10.28 |
