read.csv를 하는 데 있어서 pd.read.csv로 읽는다. 이처럼 읽을 경우 data는 데이터 프레임 형태로 만들어진다.
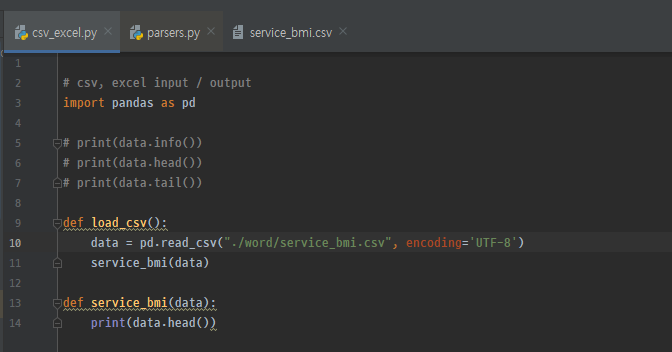
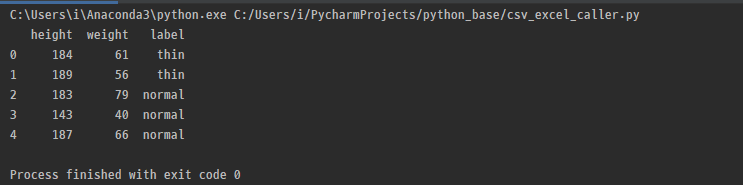
이렇게 데이터 프레임형태로 생성이 된다. pandas에서는 데이터 프레임 타입과 series 타입을 제공해준다. 데이터 프레임은 위와 같이 행 과열을 가진 형태고 series는 R의 벡터와 같은 개념이다. 하나하나의 값들을 series라고 한다.
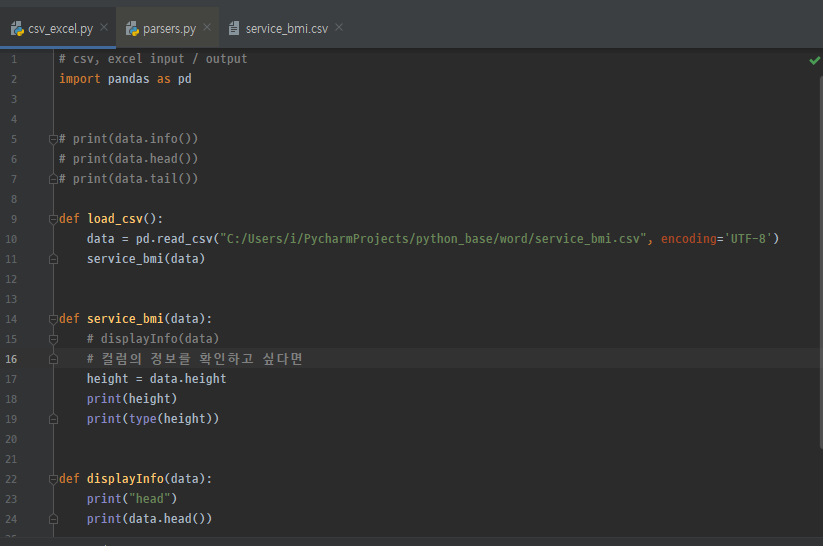
데이터 프레임의 값 접근법은 2가지가 있다. 하나는 컬럼명을 붙여주는 형태이다. 위에서는 data.height라는 값을 height에 넣어줬다. 이 height를 출력하면 아래와 같이 해당 height의 값들을 나타낸다. 이 값들의 타입은 Series이다.

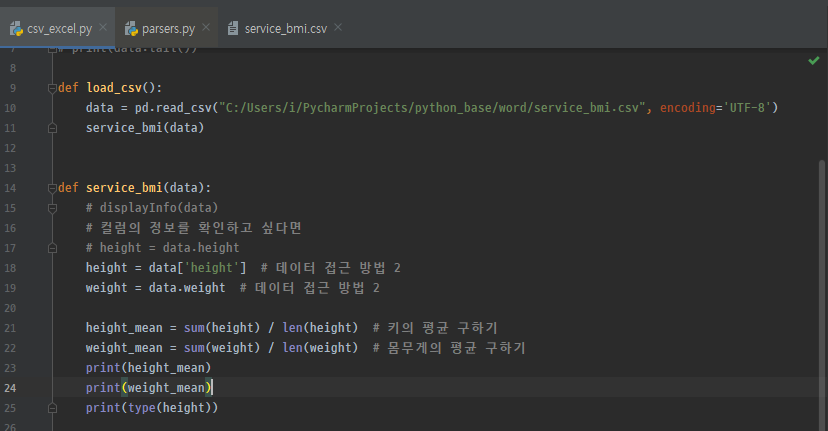
두 번째 접근 방법은 data ['칼럼명']을 통해 접근하는 방법이다. 이 두 가지 방법 다 같은 결과를 낸다.
여기서 가져온 값을 통해 평균을 구하고 있다.

max나 sum , len 등 다양한 함수들을 사용 할 수 있다.

이와 같이 결과가 나온다.
# 라벨컬럼을 활용하여 각 단어의 빈도수를 출력하는 로직
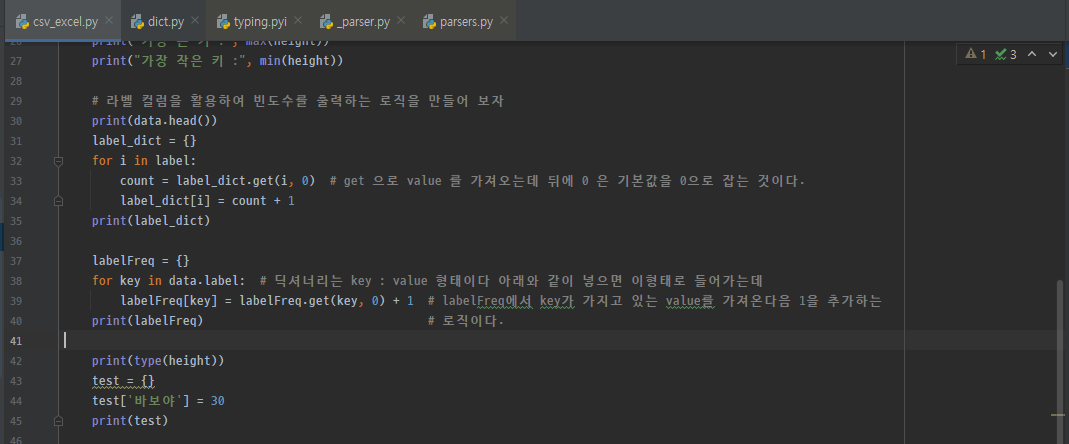
맨 처음 data.head()를 통해 데이터의 형태를 확인한다. 그 후 label_dict = {}이라는 dir 타입의 변수를 만들어준다.
그다음 for 문을 돌려 label에 있는 값을 하나씩 빼낸다.
밑에 로직으로 설명하자면 key 값은 data.labe의 한줄 한 줄을 나타낸다.
그 후 labelFreq 이라는 딕셔너리 타입에 labelFreq [key] = labelFreq.get(key,0) + 1라는 형식으로 넣는다.
labelFreq[key] 는 thin , normal, fat 등등의 값을 가진 키값의 value를 정의하는 부분이다.
labelFreq.get(key,0) + 1 이 부분은 지금 labelFreq.get에서
get 이라는 함수를 통해 labelFreq의 value의 값을 가져온다. 그때 그 value의 키는 (key, 0)에 들어가는 key 값이 되고 0은 해당 값이 없을 시 0으로 초기화한다는 뜻이다.
결론은 labelFreq의 key에 따른 value 값을 가져와서 1씩 더하면서 카운트하고 그 값을 해당 key 값인 labelFreq[key]에
넣어준다. 결괏값은 아래와 같다.
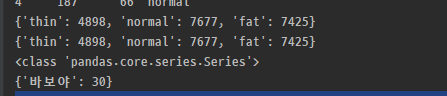
평균 간단하게 구하기

# pandas와 numpy는 추후에 다시 제대로 정리할 예정입니다.
'Base > Python' 카테고리의 다른 글
| [python] 영화 리뷰에 대한 자연어 처리분석/ 감성분석하기 feat. 스크래핑 (0) | 2020.10.07 |
|---|---|
| [python] BeautifulSoup를 통한 영화리뷰 scraping 하기 (0) | 2020.10.07 |
| [Python] 파이썬 기초 13 - 파이썬을 통한 파일 입출력 사용법 (0) | 2020.08.19 |
| [Python] 파이썬 기초 12 - 예외처리 (0) | 2020.08.19 |
| [Python] 파이썬 기초 11 - 객체의 4대 특성 ( 상속화, 캡슐화, 다형성, 추상화) (0) | 2020.08.18 |
