반응형
# 데이터 입출력
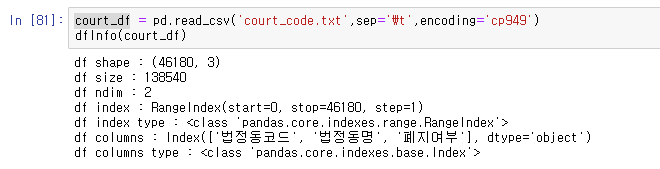
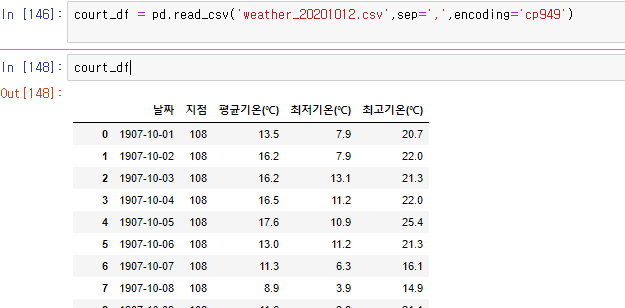
read_csv를 통해 해당 파일을 읽을 수 있다.
sep는 간격을 어떤거로 두냐는 뜻이다.
encoding 은 파일이 구성되어 있는 형식이라고 보면 된다.
#head()

맨앞에 5개의 값을 가져온다.
# tail()

맨뒤에 5개의 값을 가져온다.
# info()

데이터의 전반적인 내용을 보여준다.
예제
# 1. 폐지 여부가 존재인 것들만 데이터 프레임으로 만든다.

# str 를 통한 문자열 접근

. str을 통해 해당하는 부분의 문자열에 접근해 인덱싱을 통해 내가 원하는 식으로 출력할 수 있다.


# 특정 글자로 시작하는 startswith()

# 특정 글자로 끝나는 endswith()

#특정 글자를 포함하는 데이터만 필터링 : str.contains()

# 특정 문자(공백)를 다른 문자(_)로 대체 : str.replace()

# 공백제거(strip, lstrip, rstrip)

strip() - 전체 공백 제거

lstrip() - 왼쪽 공백 제거

rstrip() - 오른쪽 공백 제거

# 대문자 , 소문자 변환 (upper, lower, swapcase)
lower() - 소문자 변환

lower() - 대문자 변환

lower() - 대소문자 변환

실습

# 정렬 : sort_values(by= , ascending=)
# 타입변환 : astype(type)


#rank
rank를 통해 순위를 매겨준다.


rank 줬던 것의 타입을 astype 을통해 바꿔주고 해당 rank를 기존에 있던 sort_df에 새로운 칼럼명으로
값을 넣어준다. 그러면 위에화 같이 count에 따라 순위가 매겨진 걸 볼 수 있다.
#실습




이 상황에서는 합쳐지지 않는다. 배열의 인덱스가 다르기 때문이다.

그래서 m_df의 index를 초기화해준다

그 후 다 시 합치면 정상적으로 합쳐진다.

마지막으로 rank를 통해 순위를 매기고 그것을 새로운 변수에 넣어준다.
반응형
'Base > Python' 카테고리의 다른 글
| [Python] Pandas 사용법 - 다양한 인덱스 함수(reset_index,set_index,sort_index) (0) | 2020.10.16 |
|---|---|
| [Python] Pandas 사용법 - 인덱싱 접근,데이터 조작, 인덱스조작(loc,iloc) (0) | 2020.10.16 |
| [Python] Pandas 사용법 - DataFrame 생성, 추가 , 수정, 삭제, indexing (0) | 2020.10.15 |
| [Python] Pandas 사용법 - series 에 대한 추가 , 수정, 삭제, 연산, 결측치 (0) | 2020.10.14 |
| [Python] Pandas의 이론과 기초적인 사용법 (0) | 2020.10.14 |
