[Python] Pandas의 이론과 기초적인 사용법
# Pandas
컴퓨터 프로그래밍에서 pandas는 데이터 조작 및 분석을 위해 Python 프로그래밍 언어로 작성된 소프트웨어 라이브러리입니다. 특히 숫자 테이블과 시계열을 조작하기 위한 데이터 구조와 연산을 제공합니다.
- 분석할려는 데이터는 대부분 시계열(Series) 이거나 표(table) 형태로 정의해야 한다.
- 1차원의 Series 클래스와 2차원의 DataFrame 클래스를 제공한다.

import pandas as pd - 기본 import 하는 방법이다.
#Series 생성
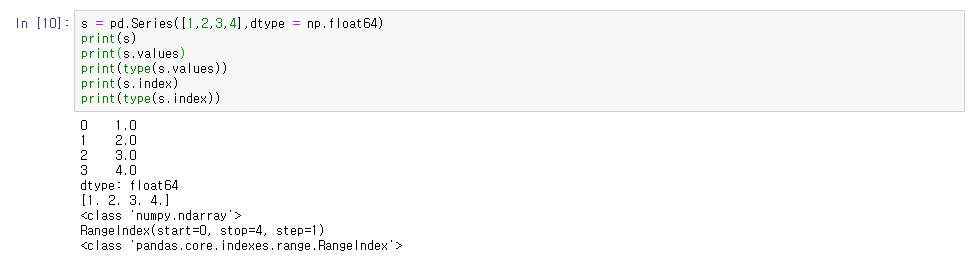
value = pd.Series([data])#Series와 numpy array를 비교

array는 여러 타입의 값들이 들어갈 수 있지만
의 형태고 Series를 만들 수 있다. dtype는 Series의 타입을 지정해준다.
Series는 같은 타입의 값들이 들어가야 된다.

간단하게 여러 형태로 값을 보기 위해 간단한 함수를 만들었다.

series를 만들고 , index=[인덱스 값]을 통해서 해당 series의 인덱스를 부여할 수 있다.

이런 식으로 arrange를 이용해서 인덱스를 만들 수 있다.

인덱스를 한글로도 가능하다.

dtype을 바꿔 줄 수도 있다.

또한 이렇게 series.index.name = 이름 series. s의 index 자체의 이름을 지어줄 수 있다.

series를 연산자를 통해 연산할 수 있다.
#series indexing

# series slicing

# series in

# dictonary를 통한 Series


# Fancy indexing , boolean indexing


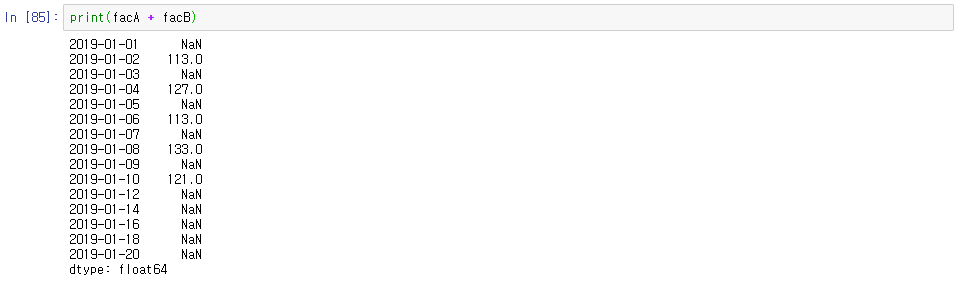
아래에 있는 index가 먼저이다. 이때 이름이 안 맞으면 아래 index에 만 있는 값은 Nan이 되어 나온다.
# 예제)




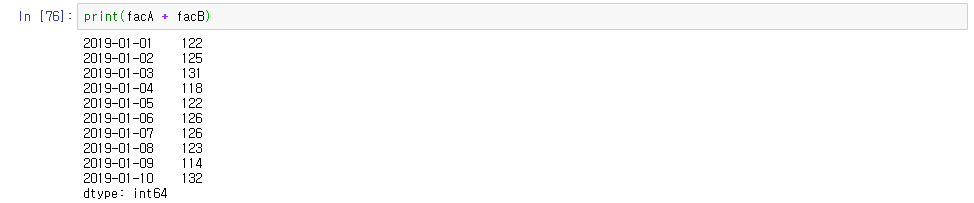
이런 식으로 계산할 수도 있다.