# 유저에 따른 개인 영화 추천
def user_difference(data,usernumber,rating,moviedata,dropdata,reader,svd):
df = data
df_user = df[(df['userId'] == usernumber) & (df['rating'] == rating)]
df_user = df_user.set_index('movieId')
df_user = df_user.join(moviedata)['original_title']
print(df_user)
user_release_ratio_list = user_release_ratio(df, usernumber) # 유저의 년도 비율을 가져온다.
user_df = moviedata.copy()
user_df = user_df[~user_df['movieId'].isin(dropdata)]
data1 = Dataset.load_from_df(df[['userId', 'movieId', 'rating']], reader)
trainset = data1.build_full_trainset()
svd.fit(trainset)
user_df['Estimate_Score'] = user_df['movieId'].apply(lambda x: svd.predict(usernumber, x).est)
# user_df = user_df.drop('movieId', axis = 1)
user_df = user_df.sort_values('Estimate_Score', ascending=False)
print(user_df.head(10))
return user_df
user_df665 = user_difference(df,665,5,meta,drop_movie_list,reader,svd)
user_df664 = user_difference(df,664,5,meta,drop_movie_list,reader,svd)
s 여기서 여러 가지 매개변수를 통해 함수를 구성하였다.
data - df ( 사용자들의 리뷰 데이터 )
usernumber - 사용자의 userid
rating - 평점이 몇 점일 때 여기서는 5점으로 주었다.
moviedata - 영화 메타 데이터를 넣어주었다.
dropdata - 사용하지 않을 영화 리스트를 뽑아서 따로 빼주었다.
reader - reader라는 함수를 넣어줬다.
svd - 알고리즘 명
이렇게 값을 넣고 간단한 전처리를 하고 svd를 돌린다.
SVD 알고리즘을 우리가 가지고 있는 trainset으로 fit을 한다. 이 작업을 해야 각 알고리즘이 우리가 가지 데이터에 맞춰서 잘 작동하게 된다. 그다음 이 SVD를 통해 예측을 한다.
여기서는 유저가 가지고 있는 movieid를 넣었을 때 svd를 통해 예측을 하고 그 값을 user_df에서 estimate_score라는 새로운 칼럼을 만든다. 그다음 sort_values를 통해 정렬을 해준다. 이것의 결과값을 보면

user664에 대한 영화 추천 결과이다.
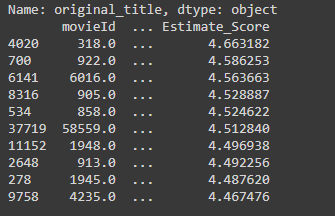
user 665에 대한 영화 추천 결과이다.
이렇게 해당유저가 본 영화에 따라 달라지는 결과를 볼 수 있다.
#유저의 변화에 따른 영화추천
def user_difference(data,usernumber,rating,moviedata,dropdata,reader,svd):
df = data
df_user = df[(df['userId'] == usernumber) & (df['rating'] == rating)]
df_user = df_user.set_index('movieId')
df_user = df_user.join(moviedata)['original_title']
print(df_user)
user_release_ratio_list = user_release_ratio(df, usernumber) # 유저의 년도 비율을 가져온다.
user_df = moviedata.copy()
user_df = user_df[~user_df['movieId'].isin(dropdata)]
data1 = Dataset.load_from_df(df[['userId', 'movieId', 'rating']], reader)
trainset = data1.build_full_trainset()
svd.fit(trainset)
user_df['Estimate_Score'] = user_df['movieId'].apply(lambda x: svd.predict(usernumber, x).est)
# user_df = user_df.drop('movieId', axis = 1)
user_df = user_df.sort_values('Estimate_Score', ascending=False)
print(user_df.head(10))
return user_df
user_1 = user_difference(df,1,5,meta,drop_movie_list,reader,svd)
df2 = df
df2.loc[1] = [1,5502,5.0]
df2.loc[2] = [1,5991.0,5.0]
add_user_1 = user_difference(df2,1,5,meta,drop_movie_list,reader,svd)
이 부분을 보면 user 1에 대한 영화 추천을 한다. 처음에는 user1에 대한 영화 추천을 한 뒤 밑에서 해당 유저가 본 영화를 추가해준 다음 영화 추천을 다시 해주었다.
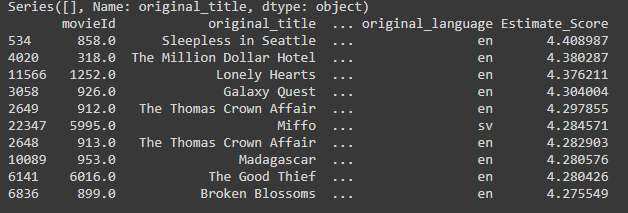
이게 첫 번째 영화 추천을 했을 때의 결과이다.

이게 사용자가 영화 리뷰를 등록함에 따라 바뀌는 결과를 볼 수 있다. movie id 가 달라진 걸 볼 수 있다.
#변수에 대한 가중치
이 부분은 변수에 대한 가중치를 주기 위해 추가한 부분이다. 알고리즘만으로 추천을 한다면 이 부분은 생략해도 상관없다.
movies_metadata.csv를 보면 다양한 정보가 있다. 그중에 나는 영화 개봉 연도의 변수를 사용하기로 했다. 콘텐츠 기반의 유사성을 통해 추천을 주기 위해 movies_metadata의 개봉 연도를 뽑아내고 이것을 사용자의 rating과 매칭 했다.
def user_release_ratio(df, usernumber):
user_df =df[df['userId'] == usernumber]
meta2 = pd.read_csv('../content/drive/My Drive/data/the-movies-dataset/movies_metadata.csv',low_memory=False)
value_meta = meta2[['id','original_title','release_date', 'genres']]
value_meta = value_meta.rename(columns={'id':'movieId'})
value_meta.movieId = pd.to_numeric(value_meta.movieId, errors='coerce')
value_meta = value_meta.dropna(axis=0)
value_meta = value_meta.reset_index()
merge_data = pd.merge(user_df, value_meta, on='movieId', how='left')
merge_data = merge_data.dropna(axis=0)
merge_data = merge_data.reset_index()그걸 merge를 통해 두 데이터를 합쳤고 결측치를 처리한 뒤 reset_index로 index를 초기화해주었다.
release_date_list = {'1900':0,'1950':0,'1960':0,'1970':0,'1980':0,'1990':0,'2000':0,'2010':0,'2020':0}
for i in range(0,len(merge_data)):
if int(merge_data['release_date'].loc[i][0:4]) <= 1900:
release_date_list["1900"] += 1
elif int(merge_data['release_date'].loc[i][0:4]) <= 1950:
release_date_list["1950"] += 1
elif int(merge_data['release_date'].loc[i][0:4]) <= 1960:
release_date_list["1960"] += 1
elif int(merge_data['release_date'].loc[i][0:4]) <= 1970:
release_date_list["1970"] += 1
elif int(merge_data['release_date'].loc[i][0:4]) <= 1980:
release_date_list["1980"] += 1
elif int(merge_data['release_date'].loc[i][0:4]) <= 1990:
release_date_list["1990"] += 1
elif int(merge_data['release_date'].loc[i][0:4]) <= 2000:
release_date_list["2000"] += 1
elif int(merge_data['release_date'].loc[i][0:4]) <= 2010:
release_date_list["2010"] += 1
elif int(merge_data['release_date'].loc[i][0:4]) <= 2020:
release_date_list["2020"] += 1
release_date_list그다음에는 dict 형태로 값을 만들었다. 그 뒤 사용자가 평점을 줬던 영화의 개봉 연도에 따라 값을 추가해주는 방식으로 만들었다.
sum = 0
for i in release_date_list:
sum += release_date_list[i]
release_date_rate = []
for i in release_date_list:
if release_date_list[i] ==0:
continue
release_date_list[i] = round((release_date_list[i]/sum),3)
return release_date_list그다음은 해당 값들의 총합을 구하고 그 총합을 각 년도를 나눠 해당 연도의 비율을 구하였다.
def Estimate_Score_sum1(user_df, user_release_ratio_list):
user_df = user_df.dropna(axis=0)
for i in range(0,len(user_df)):
if int(user_df.iloc[i]['release_date'][0:4]) <= 1900:
user_df['Estimate_Score'].loc[user_df.index[i]] = user_df.iloc[i]['Estimate_Score'] + user_release_ratio_list['1900']
elif int(user_df.iloc[i]['release_date'][0:4]) <= 1950:
user_df['Estimate_Score'].loc[user_df.index[i]]= user_df.iloc[i]['Estimate_Score'] + user_release_ratio_list['1950']
elif int(user_df.iloc[i]['release_date'][0:4]) <= 1960:
user_df['Estimate_Score'].loc[user_df.index[i]] = user_df.iloc[i]['Estimate_Score'] + user_release_ratio_list['1960']
elif int(user_df.iloc[i]['release_date'][0:4]) <= 1970:
user_df['Estimate_Score'].loc[user_df.index[i]] = user_df.iloc[i]['Estimate_Score'] + user_release_ratio_list['1970']
elif int(user_df.iloc[i]['release_date'][0:4]) <= 1980:
user_df['Estimate_Score'].loc[user_df.index[i]] = user_df.iloc[i]['Estimate_Score'] + user_release_ratio_list['1980']
elif int(user_df.iloc[i]['release_date'][0:4]) <= 1990:
user_df['Estimate_Score'].loc[user_df.index[i]] = user_df.iloc[i]['Estimate_Score'] + user_release_ratio_list['1990']
elif int(user_df.iloc[i]['release_date'][0:4]) <= 2000:
user_df['Estimate_Score'].loc[user_df.index[i]] = user_df.iloc[i]['Estimate_Score'] + user_release_ratio_list['2000']
elif int(user_df.iloc[i]['release_date'][0:4]) <= 2010:
user_df['Estimate_Score'].loc[user_df.index[i]] = user_df.iloc[i]['Estimate_Score'] + user_release_ratio_list['2010']
elif int(user_df.iloc[i]['release_date'][0:4]) <= 2020:
user_df['Estimate_Score'].loc[user_df.index[i]] = user_df.iloc[i]['Estimate_Score'] + user_release_ratio_list['2020']
return user_df
이전에 구한 비율을 통해 영화 추천을 할 때 측정치 + 변수에 따른 가중치를 더해 추천을 해줬다.
이 함수와 더불어 추천을 해주는 함수를 만들었다.
def variable_weight(data,usernumber,rating,moviedata,dropdata,reader,algo):
df = data
df_user = df[(df['userId'] == usernumber) & (df['rating'] == rating)]
df_user = df_user.set_index('movieId')
df_user = df_user.join(moviedata)['original_title']
# print(df_user)
user_release_ratio_list = user_release_ratio(df, usernumber) # 유저의 년도 비율을 가져온다.
user_pop_ratio_list = user_pop_ratio(df, usernumber) # 유저의 popularity 비율을 가져온다.
user_language_ratio_list = user_language_ratio(df, usernumber) # 유저의 language 비율을 가져온다.
user_df = moviedata.copy()
user_df = user_df[~user_df['movieId'].isin(dropdata)]
data1 = Dataset.load_from_df(df[['userId', 'movieId', 'rating']], reader)
trainset = data1.build_full_trainset()
algo.fit(trainset)
user_df['Estimate_Score'] = user_df['movieId'].apply(lambda x: algo.predict(usernumber, x).est)
user_df = user_df.sort_values('Estimate_Score', ascending=False)
user_df_sum = Estimate_Score_sum1(user_df, user_release_ratio_list)
user_df_total = Estimate_Score_sum1(user_df, user_release_ratio_list)
user_df_sum_relase = user_df_sum.sort_values('Estimate_Score', ascending=False)
print("개봉일 별 가중치")
print(user_df_sum_relase.head(10))
return user_df_sum_relase
user_df_sum_relase = variable_weight(df,665,5,meta,drop_movie_list,reader,svd)
s 여기서 여러 가지 매개변수를 통해 함수를 구성하였다.
data - df ( 사용자들의 리뷰 데이터 )
usernumber - 사용자의 userid
rating - 평점이 몇 점일 때 여기서는 5점으로 주었다.
moviedata - 영화 메타 데이터를 넣어주었다.
dropdata - 사용하지 않을 영화 리스트를 뽑아서 따로 빼주었다.
reader - reader라는 함수를 넣어줬다.
svd - 알고리즘 명
이렇게 값을 넣고 간단한 전처리를 하고 svd를 돌린다.
SVD 알고리즘을 우리가 가지고 있는 trainset으로 fit을 한다. 이 작업을 해야 각 알고리즘이 우리가 가지 데이터에 맞춰서 잘 작동하게 된다. 그다음 이 SVD를 통해 예측을 한다.
여기서는 유저가 가지고 있는 movieid를 넣었을 때 svd를 통해 예측을 하고 그 값을 user_df에서 estimate_score라는 새로운 칼럼을 만든다. 그다음 sort_values를 통해 정렬을 해준다.
이렇게 나온 결과에 내가 만든 개봉일 별 가중치를 더해 측정치를 만들어준다.
그 결과가 아래의 영화 추천 리스트 결과이다.

# 알고리즘에 따른 추천
reader = Reader()
data = Dataset.load_from_df(df[['userId', 'movieId', 'rating']], reader)
svd = SVD()
slope = SlopeOne()
nmf = NMF()
bsl_options = {'method': 'als',
'n_epochs': 5,
'reg_u': 12,
'reg_i': 5
}
als = BaselineOnly(bsl_options=bsl_options)
als_result = cross_validate(als, data, measures=['RMSE', 'MAE'],cv=5, verbose=False) #evaluate 대신 cross_validate
slope_result = cross_validate(slope, data, measures=['RMSE', 'MAE'],cv=5, verbose=False) #evaluate 대신 cross_validate
svd_result = cross_validate(svd, data, cv = 5, measures=['RMSE', 'MAE']) #evaluate 대신 cross_validate사용
nmf_result = cross_validate(nmf, data, measures=['RMSE', 'MAE'],cv=5, verbose=False) #evaluate 대신 cross_validate여기서는 다양한 알고리즘을 사용하게 된다. svd, slope, nmf, ALS 이렇게 4가지를 사용하였다. als를 구현하는 부분은 내가 했던 부분이 아니라 소스를 따로 올리지는 않겠다. 이 ALS를 제외한 나머지 알고리즘들은 surprise에 있는 함수들로 저런 식으로 사용하면 된다. 알고리즘에 대한 자세한 설명은 생략하겠다.
각 알고리즘에 대한 성능을 보기 위해 RMSE와 MAE를 구하였다. 이것을 구할 때 cross_validate를 사용하여 교차검증을 진행한다. 이것을 하는 이유는 알고리즘이 train과 test를 잡는 부분에 따라 성능이 높게 나올 수 도 있고 과적합 될 가능성이 있다. 이것을 방지하기 위해 여기서는 5번의 교차 검증을 하였다.
여기서 RMSE와 MAE를 사용한 이유는 MSE(평균 제곱 오차)가 수학적 분석이 쉬우며 계산하기 쉽기 때문이다. RMSE는 MAE에 제곱근을 씌운 것이다.
이렇게 각 알고리즘의 성능을 비교할 수 있다.
이것을 print 하면

이런 식의 값이 나온다. 이 값의 평균을 보면 된다.
이제 성능을 봤으니 각각의 알고리즘을 통한 추천을 하기로 한다.
def userRec3(data,usernumber,rating,moviedata,dropdata,reader,algo):
df = data
df_user = df[(df['userId'] == usernumber) & (df['rating'] == rating)]
df_user = df_user.set_index('movieId')
df_user = df_user.join(moviedata)['original_title']
user_release_ratio_list = user_release_ratio(df, usernumber) # 유저의 년도 비율을 가져온다.
user_pop_ratio_list = user_pop_ratio(df, usernumber) # 유저의 popularity 비율을 가져온다.
user_language_ratio_list = user_language_ratio(df, usernumber) # 유저의 language 비율을 가져온다.
user_df = moviedata.copy()
user_df = user_df[~user_df['movieId'].isin(dropdata)]
data1 = Dataset.load_from_df(df[['userId', 'movieId', 'rating']], reader)
trainset = data1.build_full_trainset()
algo.fit(trainset)
user_df['Estimate_Score'] = user_df['movieId'].apply(lambda x: algo.predict(usernumber, x).est)
user_df = user_df.sort_values('Estimate_Score', ascending=False)
return user_df
als_recomend = userRec3(df,665,5,meta,drop_movie_list,reader,als)
svd_recomend = userRec3(df,665,5,meta,drop_movie_list,reader,svd)
slope_recomend = userRec3(df,665,5,meta,drop_movie_list,reader,slope)
nmf_recomend = userRec3(df,665,5,meta,drop_movie_list,reader,nmf)나머지 매개변수는 같게 하고 마지막에 함수만 수정하여 함수가 돌아가게 했다.
print(als_recomend)
print(svd_recomend)
print(slope_recomend)
print(nmf_recomend)해당 값을 결과를 출력하게 되면
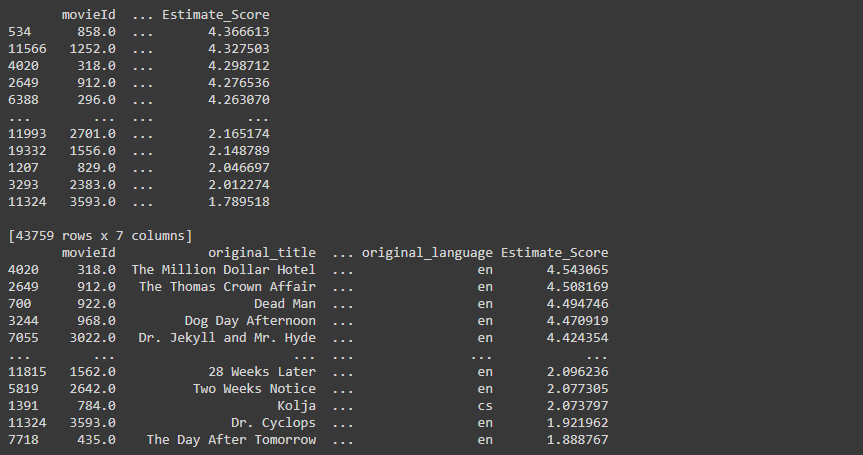

이렇게 각 알고리즘 순서대로 결과가 나오게 된다. 각 알고리즘마다 다른 영화들을 추천해주는 것을 볼 수 있다.
'Project' 카테고리의 다른 글
| [movie recomendation] 알고리즘에 따른 영화 추천 시스템 구현 - 3(시각화) (0) | 2020.10.21 |
|---|---|
| [movie recomendation] 알고리즘에 따른 영화 추천 시스템 구현 - 1 (전처리) (0) | 2020.10.18 |
| [movie recomendation] 알고리즘에 따른 영화 추천 시스템 구현 (2) | 2020.09.10 |
